Collision detection is an area of game development that scares most into using third party physics APIs due to its seemingly vertically-steep learning curve. Most programmers understand the axis-aligned bounding box (AABB) algorithm but have trouble transitioning to the more difficult algorithms such as SAT and GJK. Swept AABB is the middle player that will show a lot of the problems that can occur with normal AABB and help understand core concepts used in more advanced collision techniques.
AABB has a major fundamental problem that may not be visible at first. Take these 3 examples:
So when do these problems occur?
These problems usually appear when objects are moving fast and/or the program is running at a low frame rate. To avoid this, we need to somehow predict where the box travelled between each frame. This concept is called swept.
In this implementation, we will assume that a box is defined by a position at the top-left corner of the box and a width and height. Now that we are taking swept into consideration, we also need to remember the velocity.
So we will define our box like so:
vx and vy refer to the velocities, w and h are the box dimensions.
The function that will perform the test will look like this:
The first parameter is the box that is moving. The second is the static box that will be tested against. The last two parameters make up the normal of the collided surface. This will be used later on when we want to respond to the collision.
The return value is a number between 0 and 1 that indicates when the collision occurred. A value of 0 indicates the start of the movement and 1 indicates the end. If we get a value of 1, we can assume that there was no collision. A value of 0.5 means that the collision occurred halfway through the frame. This will also be used later to respond to the collision.
xInvEntry and yInvEntry both specify how far away the closest edges of the objects are from each other. xInvExit and yInvExit is the distance to the far side of the object. You can think of this is a being like shooting through an object; the entry point is where the bullet goes through, and the exit point is where it exits from the other side. These values are the inverse time until it hits the other object on the axis. We will now use these values to take the velocity into account.
What we are doing here is dividing the xEntry, yEntry, xExit and yExit by the object’s velocity. Of course, if the velocity is zero on any axis, it will cause a divide-by-zero error. These new variables will give us our value between 0 and 1 of when each collision occurred on each axis. The next step is to find which axis collided first.
entryTime will tell use when the collision first occurred and exitTime will tell us when it exited the object from the other side. This can be useful for certain effects, but at the moment, we just need it to calculate if a collision occurred at all.
The if statement checks to see if there was a collision or not. If the collision time was not within 0 and 1, then obviously there was no collision during this frame. Also, the time when the collision first entered should never be after when it exited out the other side. This is checked, and if it failed, then we assume that there was no collision. We specify 1 to indicate that there was no collision.
If there was a collision, our last step is to calculate the normal of the edge that was collided with.
Since all of our boxes are axis-aligned, we can assume that there are only 4 possible normals (one for each edge of the box). This simple test will figure that out and then return the collision entry time.
This is all of the code we will use for swept AABB but it won't work correctly in certain cases! That is because we need to implement broadphase (we will cover this soon). But, for now, there is a whole other step in a collision, and that is the response.
A collision response is how we want the object to behave after a collision. Before going into some of the different types of responses, we need to figure out the new point where the collision occurred. This should be easy now that we have our swept AABB function.
This is most common in games like pong where there is a ball that bounces off objects.
First we are reducing the velocity by our remaining time. Then we negate the velocity on whichever axis there was a collision. Pretty simple.
Pushing is more of the traditional “wall hugging” concept where if you run towards a wall on an angle, you will slide along the wall.
It reuses the remaining velocity and pushes it in the direction that is parallel to the collided edge. The first step is to calculate the magnitude of the velocity (this is a programmer version of the Pythagorean Theorem). The next step is performing the dot product with the velocity and the normal of the collided face. We must then normalize this scalar (because we are going to set our own distance). The final step is to multiply the normalized dot product, the switched normal and the magnitude.
Alternatively, you could normalize the velocity after calculating the magnitude, so then you don’t have to normalize dotprod.
The problem with the push technique is that it may push the object along faster than expected. A more realistic approach is to do sliding.
The first thing to remember is that we are swapping the normals around (swap x value with y value). We calculate the dot product, multiply it by the magnitude, and finally multiply it by the swapped normal value. And now we should have our projected velocity.
The swept AABB algorithm runs pretty fast, but as more objects come into play, the performance will drop rapidly. A way to combat this is called broad-phasing. This is where you can do a faster, less accurate test to quickly determine if there isn’t a collision. There are a few techniques to do this (such as circular distance) but, because our objects are all axis-aligned boxes, it makes sense to use a box again.
This first step is to calculate the broad-phase area. As bad as this looks, all it is doing is adding the velocity to the edge (depending on the direction of the velocity). Now all we have to do is a generic AABB test.
This is a rather simplified function that returns true if a collision occurred.
Now we should be able to put all of the pieces together like this:
The implementation described here has some limitations that you may have figured out already. These include:
All of the C/C++ code specified in this article is available for download here. I have also implemented it in C#. This example code will not run a demonstration; it shows only the functions involved.
And, just for the hell of it, here’s a picture of everything in action:
What is Swept?
AABB has a major fundamental problem that may not be visible at first. Take these 3 examples:
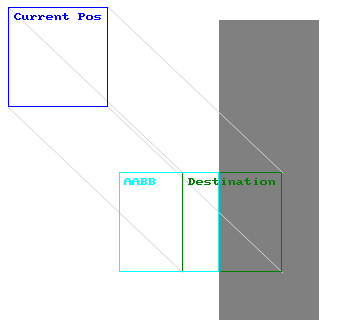
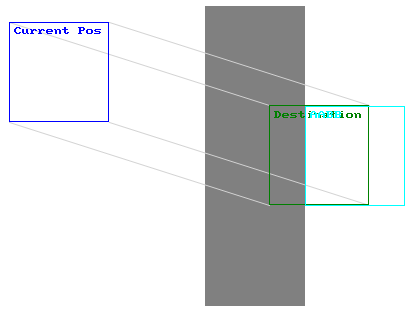

So when do these problems occur?
These problems usually appear when objects are moving fast and/or the program is running at a low frame rate. To avoid this, we need to somehow predict where the box travelled between each frame. This concept is called swept.
Implementing Swept AABB
In this implementation, we will assume that a box is defined by a position at the top-left corner of the box and a width and height. Now that we are taking swept into consideration, we also need to remember the velocity.
So we will define our box like so:
// describes an axis-aligned rectangle with a velocity
struct Box
{
// position of top-left corner
float x, y;
// dimensions
float w, h;
// velocity
float vx, vy;
};
vx and vy refer to the velocities, w and h are the box dimensions.
The function that will perform the test will look like this:
float SweptAABB(Box b1, Box b2, float& normalx, float& normaly)
The first parameter is the box that is moving. The second is the static box that will be tested against. The last two parameters make up the normal of the collided surface. This will be used later on when we want to respond to the collision.
The return value is a number between 0 and 1 that indicates when the collision occurred. A value of 0 indicates the start of the movement and 1 indicates the end. If we get a value of 1, we can assume that there was no collision. A value of 0.5 means that the collision occurred halfway through the frame. This will also be used later to respond to the collision.

float xInvEntry, yInvEntry;
float xInvExit, yInvExit;
// find the distance between the objects on the near and far sides for both x and y
if (b1.vx > 0.0f)
{
xInvEntry = b2.x - (b1.x + b1.w);
xInvExit = (b2.x + b2.w) - b1.x;
}
else
{
xInvEntry = (b2.x + b2.w) - b1.x;
xInvExit = b2.x - (b1.x + b1.w);
}
if (b1.vy > 0.0f)
{
yInvEntry = b2.y - (b1.y + b1.h);
yInvExit = (b2.y + b2.h) - b1.y;
}
else
{
yInvEntry = (b2.y + b2.h) - b1.y;
yInvExit = b2.y - (b1.y + b1.h);
}
xInvEntry and yInvEntry both specify how far away the closest edges of the objects are from each other. xInvExit and yInvExit is the distance to the far side of the object. You can think of this is a being like shooting through an object; the entry point is where the bullet goes through, and the exit point is where it exits from the other side. These values are the inverse time until it hits the other object on the axis. We will now use these values to take the velocity into account.
// find time of collision and time of leaving for each axis (if statement is to prevent divide by zero)
float xEntry, yEntry;
float xExit, yExit;
if (b1.vx == 0.0f)
{
xEntry = -std::numeric_limits<float>::infinity();
xExit = std::numeric_limits<float>::infinity();
}
else
{
xEntry = xInvEntry / b1.vx;
xExit = xInvExit / b1.vx;
}
if (b1.vy == 0.0f)
{
yEntry = -std::numeric_limits<float>::infinity();
yExit = std::numeric_limits<float>::infinity();
}
else
{
yEntry = yInvEntry / b1.vy;
yExit = yInvExit / b1.vy;
}
What we are doing here is dividing the xEntry, yEntry, xExit and yExit by the object’s velocity. Of course, if the velocity is zero on any axis, it will cause a divide-by-zero error. These new variables will give us our value between 0 and 1 of when each collision occurred on each axis. The next step is to find which axis collided first.
// find the earliest/latest times of collision
float entryTime = std::max(xEntry, yEntry);
float exitTime = std::min(xExit, yExit);
entryTime will tell use when the collision first occurred and exitTime will tell us when it exited the object from the other side. This can be useful for certain effects, but at the moment, we just need it to calculate if a collision occurred at all.
// if there was no collision
if (entryTime > exitTime || xEntry < 0.0f && yEntry < 0.0f || xEntry > 1.0f || yEntry > 1.0f)
{
normalx = 0.0f;
normaly = 0.0f;
return 1.0f;
}
The if statement checks to see if there was a collision or not. If the collision time was not within 0 and 1, then obviously there was no collision during this frame. Also, the time when the collision first entered should never be after when it exited out the other side. This is checked, and if it failed, then we assume that there was no collision. We specify 1 to indicate that there was no collision.
If there was a collision, our last step is to calculate the normal of the edge that was collided with.
else // if there was a collision
{
// calculate normal of collided surface
if (xEntry > yEntry)
{
if (xInvEntry < 0.0f)
{
normalx = 1.0f;
normaly = 0.0f;
}
else
{
normalx = -1.0f;
normaly = 0.0f;
}
}
else
{
if (yInvEntry < 0.0f)
{
normalx = 0.0f;
normaly = 1.0f;
}
else
{
normalx = 0.0f;
normaly = -1.0f;
}
}
// return the time of collision
return entryTime;
}
Since all of our boxes are axis-aligned, we can assume that there are only 4 possible normals (one for each edge of the box). This simple test will figure that out and then return the collision entry time.
This is all of the code we will use for swept AABB but it won't work correctly in certain cases! That is because we need to implement broadphase (we will cover this soon). But, for now, there is a whole other step in a collision, and that is the response.
Responses
A collision response is how we want the object to behave after a collision. Before going into some of the different types of responses, we need to figure out the new point where the collision occurred. This should be easy now that we have our swept AABB function.
float normalx, normaly;
float collisiontime = SweptAABB(box, block, out normalx, out normaly);
box.x += box.vx * collisiontime;
box.y += box.vy * collisiontime;
float remainingtime = 1.0f - collisiontime;

Deflecting
This is most common in games like pong where there is a ball that bounces off objects.

// deflect
box.vx *= remainingtime;
box.vy *= remainingtime;
if (abs(normalx) > 0.0001f)
box.vx = -box.vx;
if (abs(normaly) > 0.0001f)
box.vy = -box.vy;
First we are reducing the velocity by our remaining time. Then we negate the velocity on whichever axis there was a collision. Pretty simple.
Push
Pushing is more of the traditional “wall hugging” concept where if you run towards a wall on an angle, you will slide along the wall.

// push
float magnitude = sqrt((box.vx * box.vx + box.vy * box.vy)) * remainingtime;
float dotprod = box.vx * normaly + box.vy * normalx;
if (dotprod > 0.0f)
dotprod = 1.0f;
else if (dotprod < 0.0f)
dotprod = -1.0f;
NewBox.vx = dotprod * normaly * magnitude;
NewBox.vy = dotprod * normalx * magnitude;
It reuses the remaining velocity and pushes it in the direction that is parallel to the collided edge. The first step is to calculate the magnitude of the velocity (this is a programmer version of the Pythagorean Theorem). The next step is performing the dot product with the velocity and the normal of the collided face. We must then normalize this scalar (because we are going to set our own distance). The final step is to multiply the normalized dot product, the switched normal and the magnitude.
Alternatively, you could normalize the velocity after calculating the magnitude, so then you don’t have to normalize dotprod.
Slide
The problem with the push technique is that it may push the object along faster than expected. A more realistic approach is to do sliding.

// slide
float dotprod = (box.vx * normaly + box.vy * normalx) * remainingtime;
NewBox.vx = dotprod * normaly;
NewBox.vy = dotprod * normalx;
The first thing to remember is that we are swapping the normals around (swap x value with y value). We calculate the dot product, multiply it by the magnitude, and finally multiply it by the swapped normal value. And now we should have our projected velocity.
Broad-Phasing
The swept AABB algorithm runs pretty fast, but as more objects come into play, the performance will drop rapidly. A way to combat this is called broad-phasing. This is where you can do a faster, less accurate test to quickly determine if there isn’t a collision. There are a few techniques to do this (such as circular distance) but, because our objects are all axis-aligned boxes, it makes sense to use a box again.

Box GetSweptBroadphaseBox(Box b)
{
Box broadphasebox;
broadphasebox.x = b.vx > 0 ? b.x : b.x + b.vx;
broadphasebox.y = b.vy > 0 ? b.y : b.y + b.vy;
broadphasebox.w = b.vx > 0 ? b.vx + b.w : b.w - b.vx;
broadphasebox.h = b.vy > 0 ? b.vy + b.h : b.h - b.vy;
return broadphasebox;
}
This first step is to calculate the broad-phase area. As bad as this looks, all it is doing is adding the velocity to the edge (depending on the direction of the velocity). Now all we have to do is a generic AABB test.
bool AABBCheck(Box b1, Box b2)
{
return !(b1.x + b1.w < b2.x || b1.x > b2.x + b2.w || b1.y + b1.h < b2.y || b1.y > b2.y + b2.h);
}
This is a rather simplified function that returns true if a collision occurred.
Now we should be able to put all of the pieces together like this:
// box is the moving box
// block is the static box
Box broadphasebox = GetSweptBroadphaseBox(box);
if (AABBCheck(broadphasebox, block))
{
float normalx, normaly;
float collisiontime = SweptAABB(box, block, out normalx, out normaly);
box.x += box.vx * collisiontime;
box.y += box.vy * collisiontime;
if (collisiontime < 1.0f)
{
// perform response here
}
}
Limitations
The implementation described here has some limitations that you may have figured out already. These include:
- Doesn’t take resizing into consideration (i.e. if a box resizes throughout the frame).
- Only allows linear movement. If your moving box is moving in a circular fashion, it will not check where it was extended out on the curve.
- Only allows one box to be moving (i.e. if two boxes move towards each other and collide). This is something I intentionally left out as it starts to involve many of the physics concepts like mass and force.
- It is still only square shapes! You can’t even rotate them! This is obvious because the name of the algorithm sort of says that already. But if you have conquered swept AABB, then you might be ready to move onto the next level (like SAT or GJK).
- It is made for 2D only. Luckily, it is quite easy to convert this code to 3D. So long as you understand the concept well, you shouldn’t have much trouble with it. I kept it as 2D to keep things as simple as possible.
Code
All of the C/C++ code specified in this article is available for download here. I have also implemented it in C#. This example code will not run a demonstration; it shows only the functions involved.
And, just for the hell of it, here’s a picture of everything in action: