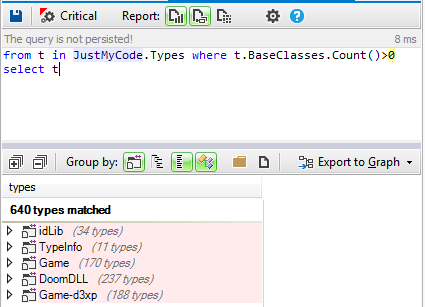
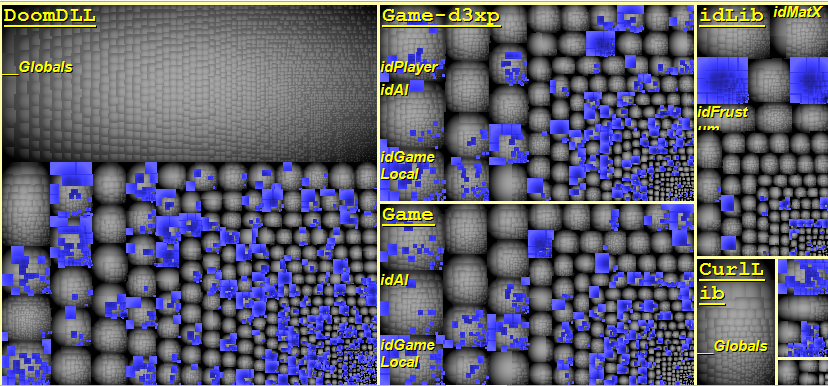
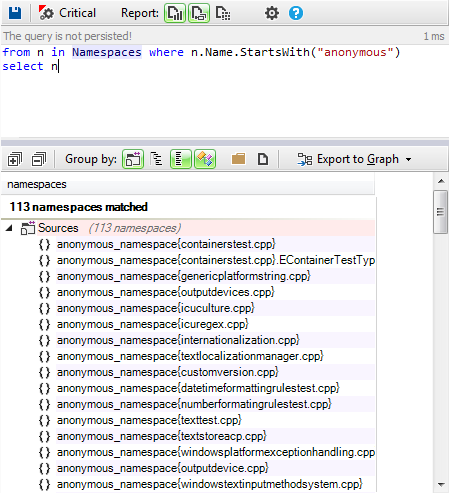
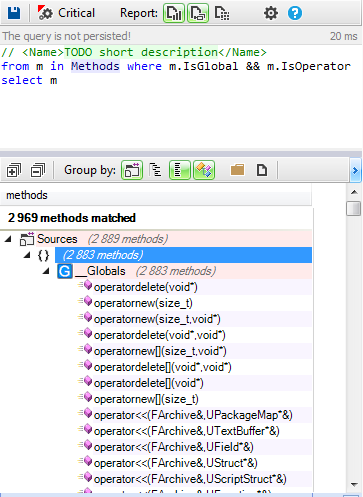
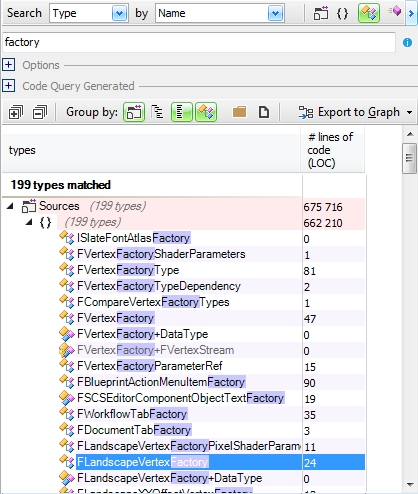
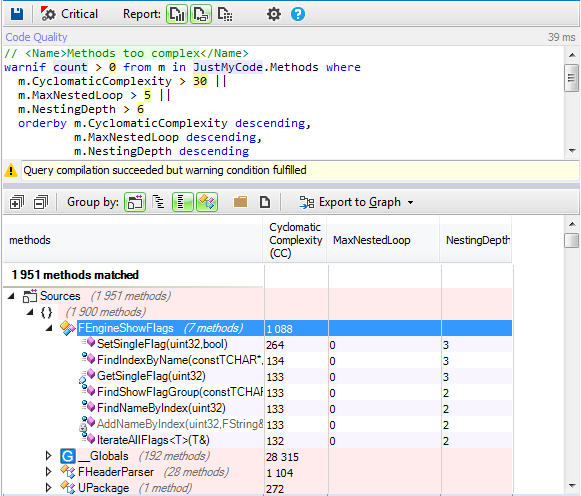
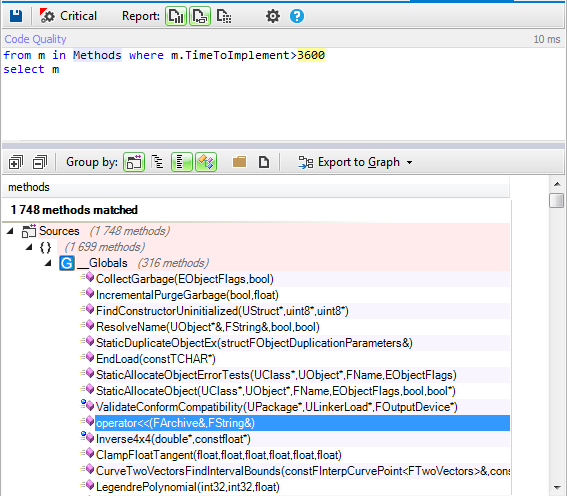
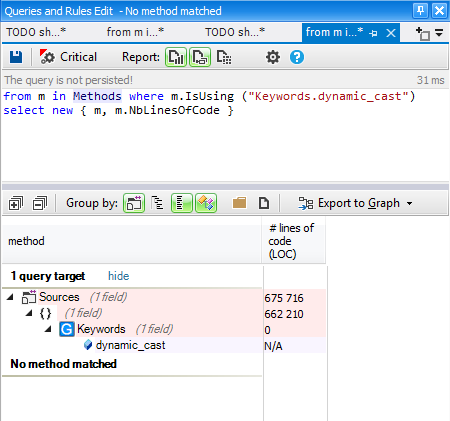
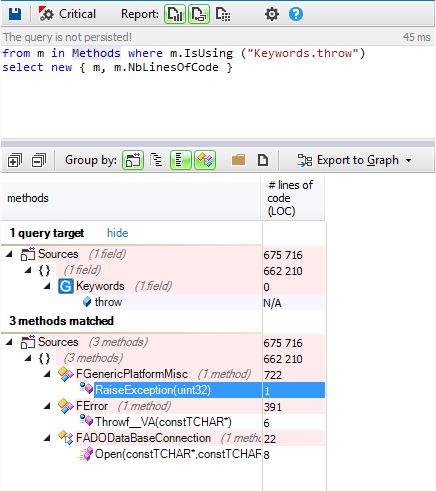
This tutorial gives a step-by-step explanation on how to create a scoreboard that shows the number of lives, the time, or the points obtained in a video game.
To give this tutorial some context, we’re going to use the example project
StunPig in which all the applications described in this tutorial can be seen. This project can be cloned from the WiMi5
Dashboard.
![image07.png]()
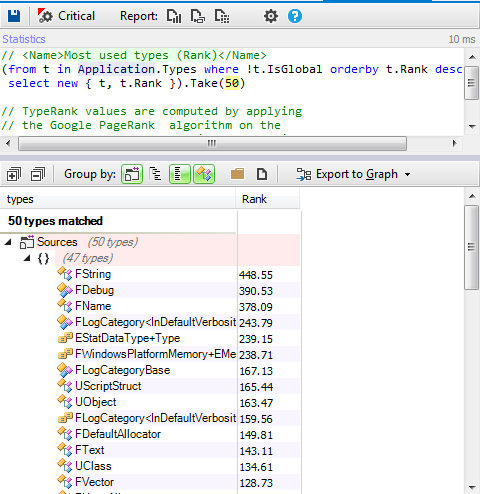
We require two graphic elements to visualize the values of the scoreboards, a “Lives” Sprite which represents the number of lives, and as many Font and Letter Sprites as needed to represent the value of the digit to be shown in each case.
The “Lives” Sprite is one with four animations or image states that are linked to each one of the four numerical values for the value of the level of lives.
![image01.png]()
![image27.png]()
The
Font or Letter Sprite, a Sprite with 11 animations or image states which are linked to each of the ten values of the numbers 0-9, as well as an extra one for the colon (:).
![image16.png]()
![image10.png]()
Example 1. How to create a lives scoreboard
To manage the lives, we’ll need a numeric value for them, which in our example is a number between 0 and 3 inclusive, and its graphic representation in our case is the three orange-colored stars which change to white as lives are lost, until all of them are white when the number of lives is 0.
![image12.png]()
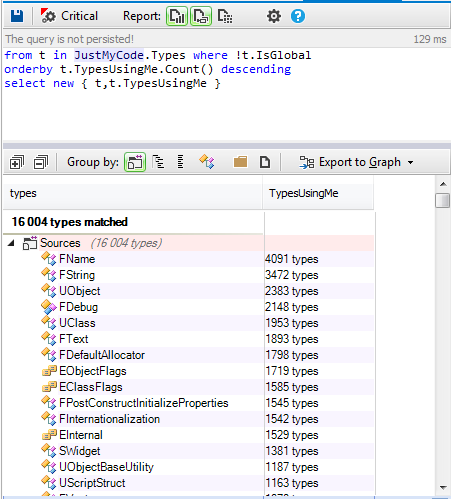
To do this, in the Scene Editor, we must create the instance of the sprite used for the stars. In our case, we’ll call them “Lives”. To manipulate it, we’ll have a Script (“
lifeLevelControl”) with two inputs (“
start” and “
reduce”), and two outputs (“
alive” and “
death”).
![image13.png]()
The “
start” input initializes the lives by assigning them a numeric value of 3 and displaying the three orange stars. The “reduce” input lowers the numeric value of lives by one and displays the corresponding stars. As a consequence of triggering this input, one of the two outputs is activated. The “
alive” output is activated if, after the reduction, the number of lives is greater than 0. The “
death” output is activated when, after the reduction, the number of lives equals 0.
Inside the Script, we do everything necessary to change the value of lives, displaying the Sprite in relation to the number of lives, triggering the correct output in function of the number of lives, and in our example, also playing a negative fail sound when the number of lives goes down..
In our “
lifeLevelControl” Script, we have a “
currentLifeLevel” parameter which contains the number of lives, and a parameter which contains the “
Lives” Sprite, which is the element on the screen which represents the lives. This Sprite has four animations of states, “0”, “1”, “2”, and “3”.
![image14.png]()
The “
start” input connector activates the
ActionOnParam “copy” blackbox which assigns the value of 3 to the
“currentLifeLevel” parameter and, once that’s done, it activates the “
setAnimation” ActionOnParam blackbox which displays the “3” animation Sprite.
The “
reduce” input connector activates the “-”
ActionOnParam blackbox which subtracts from the “
currentLifeLevel” parameter the value of 1. Once that’s done, it first activates the “
setAnimation” ActionOnParam blackbox which displays the animation or state corresponding to the value of the “
CurrentLifeLevel” parameter and secondly, it activates the “
greaterThan” Compare blackbox, which activates the “
alive” connector if the value of the “
currentLifeLevel” parameter is greater than 0, or the “
death” connector should the value be equal to or less than 0.
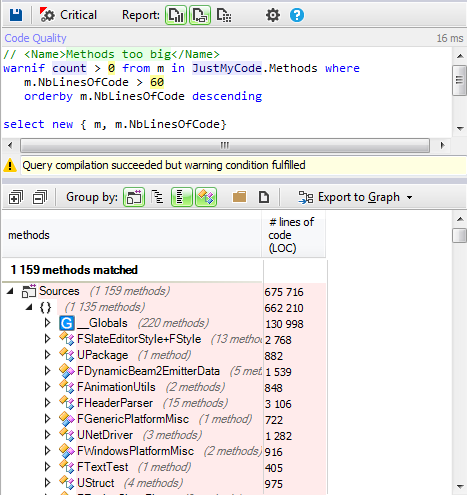
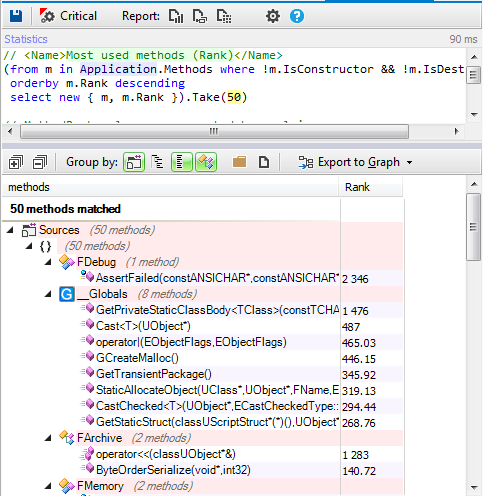
Example 2. How to create a time scoreboard or chronometer
In order to manage time, we’ll have as a base a numerical time value that will run in thousandths of a second in the round and a graphic element to display it. This graphic element will be 5 instances of a Sprite that will have 10 animations or states, which will be the numbers from 0-9.
![image10.png]()
![image20.png]()
In our case, we’ll display the time in seconds and thousandths of a second as you can see in the image, counting down; so the time will go from the total time at the start and decrease until reaching zero, finishing.
To do this in the Scenes editor, we must create the 6 instances of the different sprites used for each segment of the time display, the tenths place, the units place, the tenths of a second place, the hundredths of a second place, and the thousandths of a second place, as well as the colon. In our case, we’ll call them “
second.
unit”, “
second.
ten”, “
millisec.unit”, “
millisec.ten” y “
millisec.hundred”.
![screenshot_309.png]()
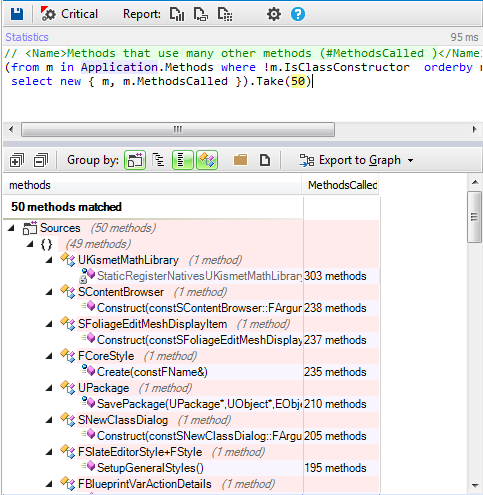
In order to manage this time, we’ll have a Script (“
RoundTimeControl”) which has 2 inputs (“
start” and “
stop”) and 1 output (“
end”), as well as an exposed parameter called “
roundMillisecs” and which contains the value of the starting time.
![image31.png]()
The “
start” input activates the countdown from the total time and displays the decreasing value in seconds and milliseconds. The “
stop” input stops the countdown, freezing the current time on the screen. When the stipulated time runs out, the “
end” output is activated, which determines that the time has run out. Inside the Script, we do everything needed to control the time and display the Sprites in relation to the value of time left, activating the “
end” output when it has run out.
In order to use it, all we need to do is put the time value in milliseconds in, either by placing it directly in the “
roundMillisecs” parameter, or by using a blackbox I assign it, and once that’s been assigned, we then activate the the “start” input which will display the countdown until we activate the “
stop” input or reach 0, in which case the “
end” output will be activated, which we can use, for example, to remove a life or whatever else we’d like to activate.
![image04.png]()
In the “
RoundTimeControl” Script, we have a fundamental parameter, “
roundMillisecs”, which contains and defines the playing time value in the round. Inside this Script, we also have two other Scripts, “
CurrentMsecs-Secs” and “
updateScreenTime”, which group together the actions I’ll describe below.
The activation of the “
start” connector activates the “
start” input of the Timer blackbox, which starts the countdown. As the defined time counts down, this blackbox updates the “
elapsedTime” parameter with the time that has passed since the clock began counting, activating its “
updated” output. This occurs from the very first moment and is repeated until the last time the time is checked, when the “
finished” output is triggered, announcing that time has run out. Given that the time to run does not have to be a multiple of the times between the update and the checkup of the time run, the final value of the
elapsedTime parameter will most likely be greater than measured, which is something that will have to be kept in mind when necessary.
The
“updated” output tells us we have a new value in the “
elapsedTime” parameter and will activate the “
CurrentTimeMsecs-Secs” Script which calculates the total time left in total milliseconds and divides it into seconds and milliseconds in order to display it. Once this piece of information is available, the “
available” output will be triggered, which will in turn activate the “
update” input of the “
updateScreenTime” Script which places the corresponding animations into the Sprites displaying the time.
In the “
CurrentMsecs-Secs” Script, we have two fundamental parameters with to carry out; “
roundMillisecs”, which contains and defines the value of playing time in the round, and “
elapsedTime”, which contains the amount of time that has passed since the clock began running. In this Script, we calculate the time left and then we break down that time in milliseconds into seconds and milliseconds--the latter is done in the “
CalculateSecsMillisecs” Script, which I’ll be getting to.
![image19-1024x323.png]()
The activation of the
get connector starts the calculation of time remaining, starting with the activation of the “-”
ActionOnParam blackbox that subtracts the value of the time that has passed since the “
elapsedTime” parameter contents started from the total run time value contained in the “
roundMillisecs” parameter. This value, stored in the “
CurrentTime” parameter, is the time left in milliseconds.
Once that has been calculated, the “
greaterThanOrEqual” Compare blackbox is activated, which compares the value contained in “
CurrentTime” (the time left) to the value 0. If it is greater than or equal to 0, it activates the “
CalculateSecsMillisecs” Script which breaks down the remaining time into seconds and milliseconds, and when this is done, it triggers the “
available” output connector. If it is less, before activating the “
CalculateSecsMillisecs” Script, we activate the
ActionOnParam “copy” blackbox which sets the time remaining value to zero.
![image30-1024x294.png]()
In the “
CalculateSecsMillisecs” Script, we have the value of the time left in milliseconds contained in the “
currentTime” parameter as an input. The Script breaks down this input value into its value in seconds and its value in milliseconds remaining, providing them to the “
CurrentMilliSecs” and “CurrentSecs” parameters. The activation of its “
get” input connector activates the
“lessThan” Compare blackbox. This performs the comparison of the value contained in the “
currentTime” parameter to see if it is less than 1000.
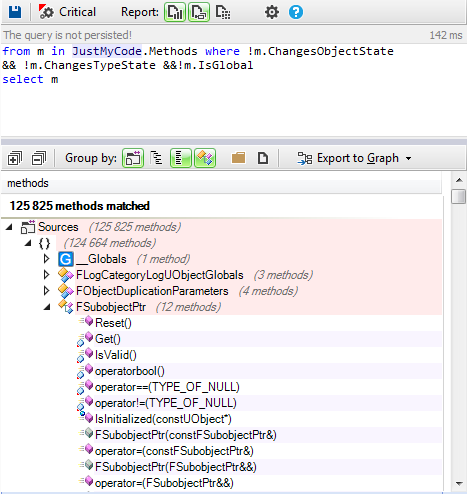
If it is less, the “
true” output is triggered. What this means is that there are no seconds, which means the whole value of “
CurrentTime” is used as a value in the “
CurrentMilliSecs” parameter, which is then copied by the “
Copy” ActionOnParam blackbox; but it doesn’t copy the seconds, because they’re 0, and that gives the value of zero to the “
currentSecs” parameter via the “
copy” ActionOnParam blackbox. After this, it has the values the Script provided, so it activates its “
done” output..
On the other hand, if the check the “
lessThan” Compare blackbox runs determines that the “
currentTime” is greater than 1000, it activates its “
false” output. This activates the “/”
ActionOnParam blackbox, which divides the “
currentTime” parameter by 1000’, storing it in the “
totalSecs” parameter. Once that is done, the “
floor” ActionOnParam is activated, which leaves its total “
totalSecs” value in the “
currentSecs” parameter.
After this, the “-”
ActionOnParam is activated, which subtracts “
currentSecs” from “
totalSecs”, which gives us the decimal part of “
totalSecs”, and stores it in “
currentMillisecs” in order to later activate the “*”
ActionOnParam blackbox, multiplying by 1000 the “
currentMillisecs” parameter which contains the decimal value of the seconds left in order to convert it into milliseconds, which is stored in the “
CurrentMillisecs” parameter (erasing the previous value). After this, it then has the values the Script provides, so it then activates its “
done” output.
When the “
CalculateSecsMillisecs” Script finishes and activates is “
done” output, and this activates the Script’s “
available” output, the “
currentTimeMsecs-Secs” Script is activated, which then activates the “
updateScreenTime” Script via its “
update” input. This Script handles displaying the data obtained in the previous Script and which are available in the “
CurrentMillisecs” and “
CurrentSecs” parameters.
![image06.png]()
The “
updateScreenTime” Script in turn contains two Scripts, “
setMilliSeconds” and “
setSeconds”, which are activated when the “
update” input is activated, and which set the time value in milliseconds and seconds respectively when their “
set” inputs are activated. Both Scripts are practically the same, since they take a time value and place the Sprites related to the units of that value in the corresponding animations. The difference between the two is that “
setMilliseconds” controls 3 digits (tenths, hundredths, and thousandths), while “
setSeconds” controls only 2 (units and tens).
![image11.png]()
The first thing the “
setMilliseconds” Script does when activated is convert the value “
currentMillisecs” is to represent to text via the “
toString” ActionOnParam blackbox. This text is kept in the “
numberAsString” parameter. Once the text has been obtained, we divide it into characters, grouping it up in a collection of Strings via the “
split” ActionOnParam. It is very important to leave the content of the “
separator” parameter of this blackbox empty, even though in the image you can see two quotation marks in the field. This collection of characters is gathered by the “
digitsAsStrings” parameter. Later, based on the value of milliseconds to be presented, it will set one animation or another in the Sprites.
Should the time value to be presented be less than 10, which is checked by the
“lessThan” Compare blackbox against the value 10, the “true” output is activated which in turn activates the “
setWith1Digit” Script. Should the time value be greater than 10, the blackbox’s “
false” output is activated, and it proceeds to check if the time value is less than 100, which is checked by the “
lessThan” Compare blackbox against the value 100. If this blackbox activates its “
true” output, this in turn activates the “
setWith2Digits” Script. Finally, if this blackbox activates the “
false” output, the “
setWith3Digits” Script is activated.
![image15.png]()
The “
setWith1Digit” Script takes the first of the collection of characters, and uses it to set the animation of the Sprite that corresponds with the units contained in the “
millisec.unit” parameter. The remaining Sprites (“
millisec.
ten” and “
millisec.
hundred”) are set with the 0 animation.
![image22.png]()
The “
setWith2Digits” Script takes the first of the collection of characters, and uses it to set the animation of the Sprite corresponding to the tenths place number contained in the “
millisec.ten” parameter, the second character of the collection to set the Sprite animation corresponding to the units contained in the “
millisec.unit” parameter and the “
millisec.hundred” Sprite is given the animation for 0.
![image29.png]()
The “
setWith3Digits” Sprite takes the first of the collection of characters, and uses it to set the animation of the Sprite corresponding to the hundredths contained in the “
millisec.hundred” parameter, the second character of the collection to set the animation of the Sprite corresponding to the tenths place value, contained in the “
millisec.ten” parameter, and the third character of the collection to set the animation of the Sprite corresponding to the units place value contained in the “
millisec.unit” parameter.
![image18.png]()
The “
setSeconds” Script when first activated converts the value to represent “
currentSecs” to text via the “
toString” ActionOnParam blackbox. This text is grouped in the “
numberAsString” parameter. Once the text is obtained, we divide it into characters, gathering it in a collection of Strings via the “
split” ActionOnParam blackbox. It is very important to leave the content of the “
separator” parameter of this Blackbox blank, even though you can see two quotation marks in the field. This collection of characters is collected in the “
digitsAsStrings” parameter. Later, based on the value of the seconds to be shown, one animation or another will be placed in the Sprites.
If the time value to be presented is less than 10, it’s checked by the
“lessThan” Compare blackbox against the value of 10, which activates the “
true” output; the first character of the collection is taken and used to set the animation of the Sprite corresponding to the units place value contained in the “
second.unit” parameter. The other Sprite, “
second.ten”, is given the animation for 0.
If the time value to be presented is greater than ten, the “
false” output of the blackbox is activated, and it proceeds to pick the first character from the collection of characters and we use it to set the animation of the Sprite corresponding to the tens place value contained in the “
second.ten” parameter, and the second character of the character collection is used to set the animation of the Sprite corresponding to the units place value contained in the “
second.unit” parameter.
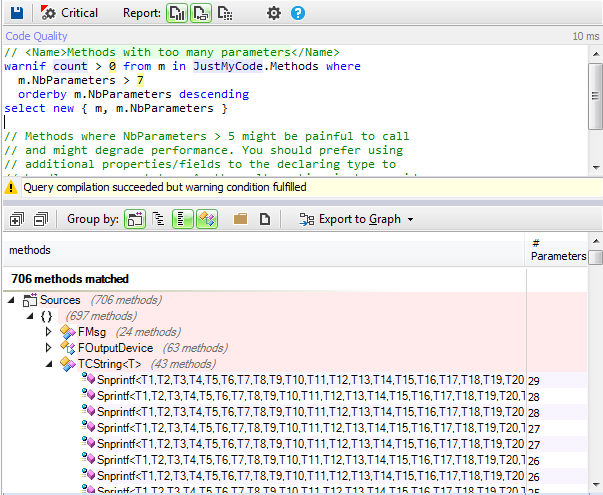
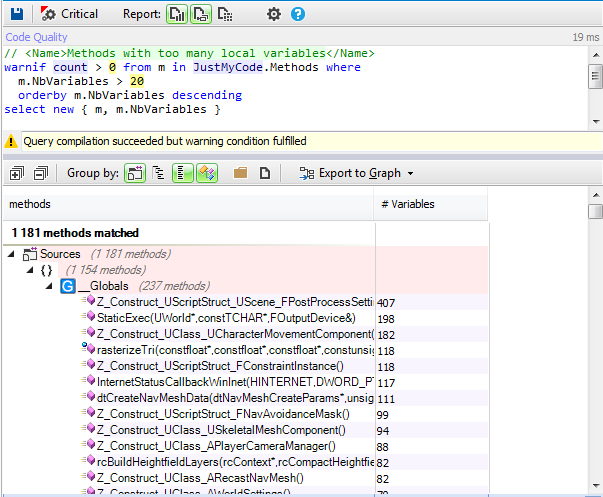
Example 3. How to create a points scoreboard.
In order to manage the number of points, we’ll have as a base the whole number value of these points that we’ll be increasing and a graphic element to display it. This graphic element will be 4 instances of a Sprite that will have 10 animations or states, which will be each of the numbers from 0 to 9.
![image10.png]()
In our case, we’ll display the points up to 4 digits, meaning scores can go up to 9999, as you can see in the image, starting at 0 and then increasing in whole numbers.
![image08.png]()
For this, in the Scene editor, we must create the four instances of the different Sprites used for each one of the numerical units to be used to count points: units, tens, hundreds, and thousands. In our case, we’ll call them “
unit point”, “
ten point”, “
hundred point”, and “
thousand point”. To manage this time, we’ll have a Script (“
ScorePoints”), which has 2 inputs (“
reset” and “
increment”), as well as an exposed parameter called “
pointsToWin” which contains the value of the points to be added in each incrementation.
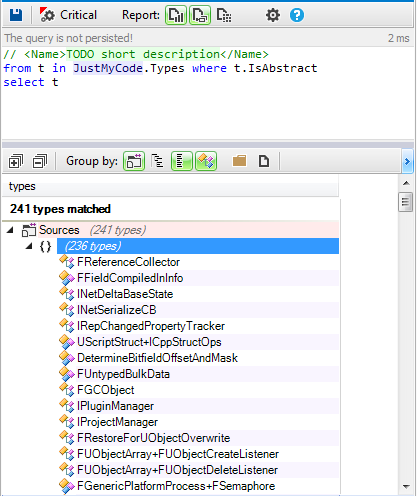
![image09.png]()
The “
reset” input sets the current score value to zero, and the “
increment” input adds the points won in each incrementation contained in the “
pointsToWin” parameter to the current score.
In order to use it, we must only set the value for the points to win in each incrementation by either putting it in the “
pointsToWin” parameter or by using a blackbox that I assign it. Once I have it, we can activate the “
increment” input, which will increase the score and show it on the screen. Whenever we want, we can begin again by resetting the counter to zero by activating the “
reset” input.
In the interior of the Script, we do everything necessary to perform these actions and to represent the current score on the screen, displaying the 4 Sprites (units, tens, hundreds, and thousands) in relation to that value. When the “
reset” input is activated, a “
copy” ActionOnParam blackbox sets the value to 0 in the “
scorePoints” parameter, which contains the value of the current score. Also, when the “
increment” input is activated, a “+”
ActionOnParam blackbox adds the parameter “
pointsToWin”, which contains the value of the points won in each incrementation, to the “
scorePoints” parameter, which contains the value of the current score. After both activations, a “
StoreOnScreen” Script is activated via its “
update” input.
![image03.png]()
The “
StoreOnScreen” Script has a connector to the “
update” input and shares the “
scorePoints” parameter, which contains the value of the current score.
![image00.png]()
![image28-1024x450.png]()
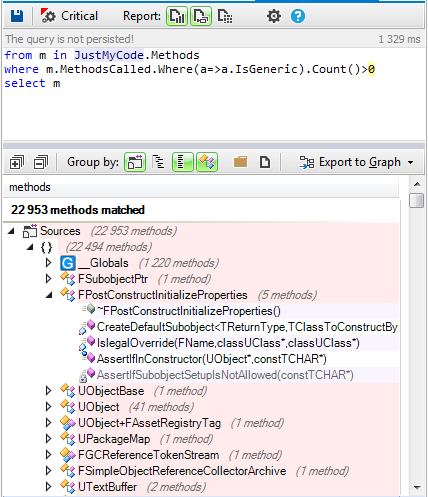
Once the “
ScoreOnScreen” Script is activated by its “
update” input, it begins converting the score value contained in the “
scorePoints” parameter into text via the “
toString” ActionOnParam blackbox. This text is gathered in the “
numberAsString” parameter. Once the text has been obtained, we divide it into characters and group them into a collection of Strings via the “
split” ActionOnParam.
This collection of characters is gathered into the “
digitsAsStrings” parameter. Later, based on the value of the score to be presented, one animation or another will be set for the 4 Sprites. If the value of the score is less than 10, as checked by the “
lessThan” Compare blackbox against the value 10, its “
true” output is activated, which activates the “
setWith1Digit” Script.
If the value is greater than 10, the blackbox’s “
false” output is activated, and it checks to see if the value is less than 100. When the
“lessThan” Compare blackbox checks that the value is less than 100, its “
true” output is activated, which in turn activates the “
setWith2Digits” Script.
If the value is greater than 100, the “
false” output of the blackbox is activated, and it proceeds to see if the value is less than 1000, which is checked by the “
lessThan” Compare blackbox against the value of 1000. If this blackbox activates its “
true” output, this will then activate the “
setWith3Digits” Script. If the blackbox activates the “
false” output, the “
setWith4Digits” Script is activated.
![image21.png]()
![image05.png]()
The “
setWith1Digit” Script takes the first character from the collection of characters and uses it to set the animation of the Sprite that corresponds to the units place contained in the “
unit.point” parameter. The remaining Sprites (“
ten.
point”, “
hundred.
point” and “
thousand.
point”) are set with the “0” animation.
![image24.png]()
![image02.png]()
The “
setWith2Digits” takes the first of the collection of characters and uses it to set the animation of the Sprite corresponding to the tens place contained in the “
ten.point” parameter, and the second character of the collection is set with the animation of the Sprite corresponding to the units place as contained in the “
units.point” parameter. The remaining Sprites (“
hundred.point”) and (“
thousand.point”) are set with the “0” animation.
![image25.png]()
![image17.png]()
The “
setWith3Digits” takes the first of the collection of characters and uses it to set the animation of the Sprite corresponding to the hundreds place contained in the “
hundred.point”) parameter; the second character in the collection is set with the animation for the Sprite corresponding to the tens place as contained in the “
ten.point” parameter; and the third character in the collection is set with the animation for the Sprite corresponding to the units place as contained in the “
unit.point” parameter. The remaining Sprite, (“
thousand.point”) is set with the “0” animation.
![image23.png]()
![image26.png]()
The “
setWith4Digits” Script takes the first character of the collection of characters and uses it to set the animation of the Sprite corresponding to the thousands place as contained in the “
thousand.point” parameter; the second is set with the animation for the Sprite corresponding to the hundreds place as contained in the “
hundred.point” parameter; the third is set with the animation for the Sprite corresponding to the tens place as contained in the “
ten.point” parameter; and the fourth is set with the animation for the Sprite corresponding to the units place as contained in the “
unit.point” parameter.
As you can see it is not necessary to write code when you work with WiMi5. The whole logic of these scoreboard has been created by dragging and dropping blackboxes in the LogicChart. You also have to set and configure parameters and scripts, but all the work is visually done. We hope you have enjoyed this tutorial and you have understood how to create scoreboards.